1 CUDA 简介
- CUDA 是:
- Compute Unified Device Architecture 的简称,意为统一计算设备架构;
- 是 NVIDIA 公司 2007 年推出的针对 GPU 的并行计算架构,能使用程序控制底层的硬件资源进行程序计算,从而解决复杂的计算问题;
- 包括了 GPU 加速库、调试和优化工具、一个 C/C++ 编译器和运行时库;
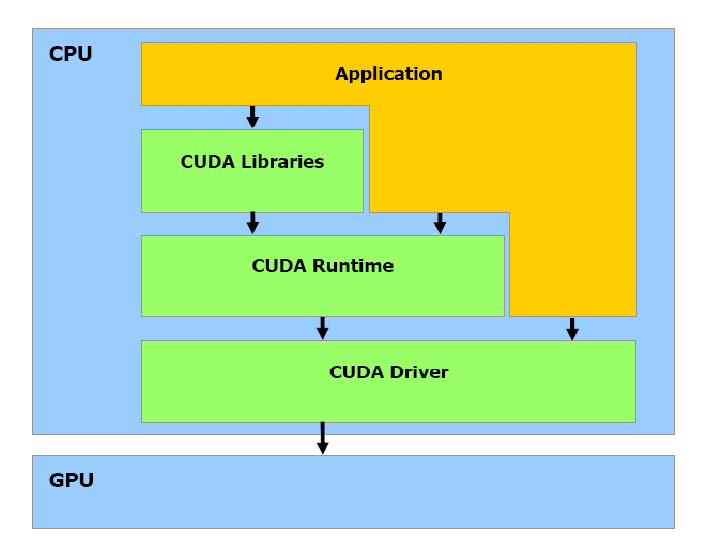
- CUDA 的软件堆栈由三层构成
- CUDA Library
- CUDA Runtime API
- CUDA Driver API
提供 CUDA 给出的应用开发库是 API 层的主要任务,大规模的并行计算问 题由它负责解决。CUDA 的核心是 CUDA C 语言,它包含对 C 语言的最小扩展集和一个运行时库,使用这些扩展和运行时库的源文件必须通过 nvcc 编译器进行编译。
- CUDA 软件体系
2 CUDA 常用术语
- 主机(Host):将 CPU 及系统的内存称为主机。
- 设备(Device):将 GPU 及 GPU 本身的显示内存称为设备,在一个系统中可以存在一个主机和若干个设备。CUDA 编程模型中,CPU 与 GPU 协同工作, CPU 负责进行逻辑性强的事务处理和串行计算,GPU 则专注于执行高度线程化的并行处理任务。CPU、GPU 各自拥有相互独立的存储器地址空间:主机端的内存和设备端的显存。
- 线程(Thread):一般通过 GPU 的一个核进行处理,可以表示成一维、二维、 三维。一个 block 中的所有 thread 在一个时刻执行指令并不一定相同。
- 线程块(Block):由多个线程组成,可以表示成一维、二维、三维;各 block 是并行执行的,block 间无法通信,也没有执行顺序;注意线程块的数量有限制 (硬件限制)。Block 内,可以通过 “
__syncthreads()”进行线程同步;thread 间通过“shared memory”进行通信。在实际运行中,block 会被分割成更小的线程束(warp)。线程束的大小由硬件的计算能力版本决定。Warp 中的线程只与thread ID有关,而与 block 的维度和每一维的尺度没有关系。 - 线程格(Grid):由多个线程块组成,可以表示成一维、二维、三维。
- 线程束:在 CUDA 架构中,线程束是指一个包含 32 个线程的集合,这个线程集合被编织在一起并且步调一致的形式执行,在程序中的每一行,线程束中的每个线程都将在不同数据上执行相同的命令。
- 核函数(Kernel):运行在 GPU 上的 CUDA 并行计算函数称为 kernel(内核函数)。内核函数必须通过
__global__函数类型限定符定义,并且只能在主机端代码中调用。在调用时,必须声明内核函数的执行参数即”<<< >>>”,用于说 明内涵函数中的线程数量,以及线程是如何组织的。不同计算能力的设备对线程的总数和组织方式有不同的约束。必须先为 Kernel 中用到的数组或变量分配好足够的空间,再调用 kernel 函数,否则在 GPU 计算时会发生错误, 例如越界或报错,甚至导致蓝屏和死机。
3 CUDA 安装
3.1 硬件需求
机器需要具备 NVIDIA 的显卡
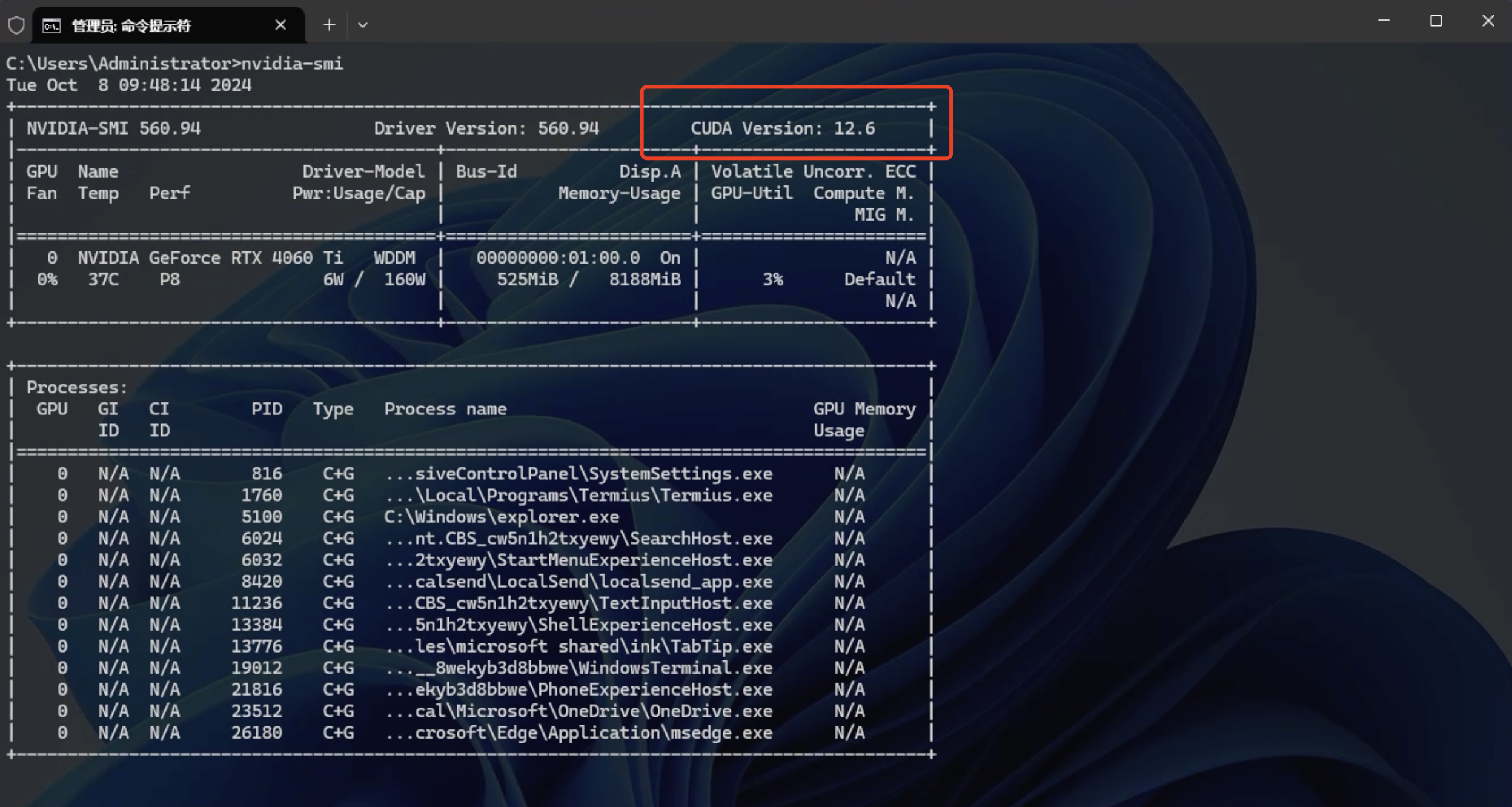
- 检查 N 卡驱动并查看支持的 CUDA 版本
Win + R,然后输入cmd并回车打开cmd窗口- 输入
nvidia-smi查看显卡驱动信息- 若命令无法识别,则表示系统中未安装显卡驱动,需要先安装驱动
- 这里可以看到显卡支持的 CUDA 版本为 12.6
3.2 安装 Visual Studio
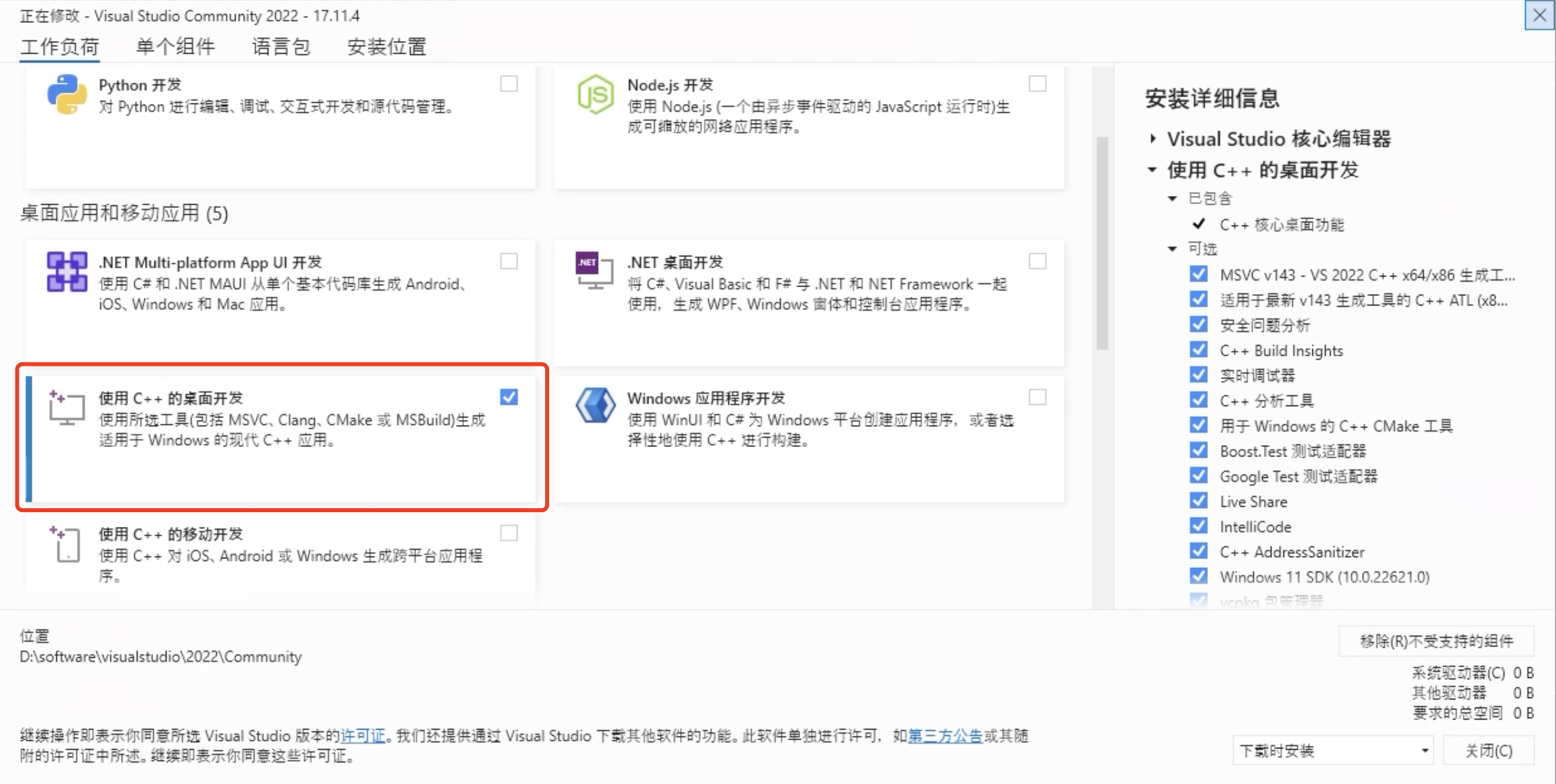
由于 cuda 开发工具依赖于Microsoft Visual C++ (MSVC) 编译器,而 Visual Studio 已经内置 MSVC,同时,CUDA 开发环境与 Visual Studio 紧密集成,可以让开发者在 Visual Studio 中直接编写、调试和管理 CUDA 项目,当然,Visual Studio 不是必须的,但是必须安装 MSVC。但如果你是新手,建议直接安装 Visual Studio。
- Visual Studio 下载链接:https://visualstudio.microsoft.com/zh-hans/downloads/
- 安装时,勾选安装 C++ 桌面开发组件,其包含了我们所需的 MSVC
3.3 安装 CUDA 工具包
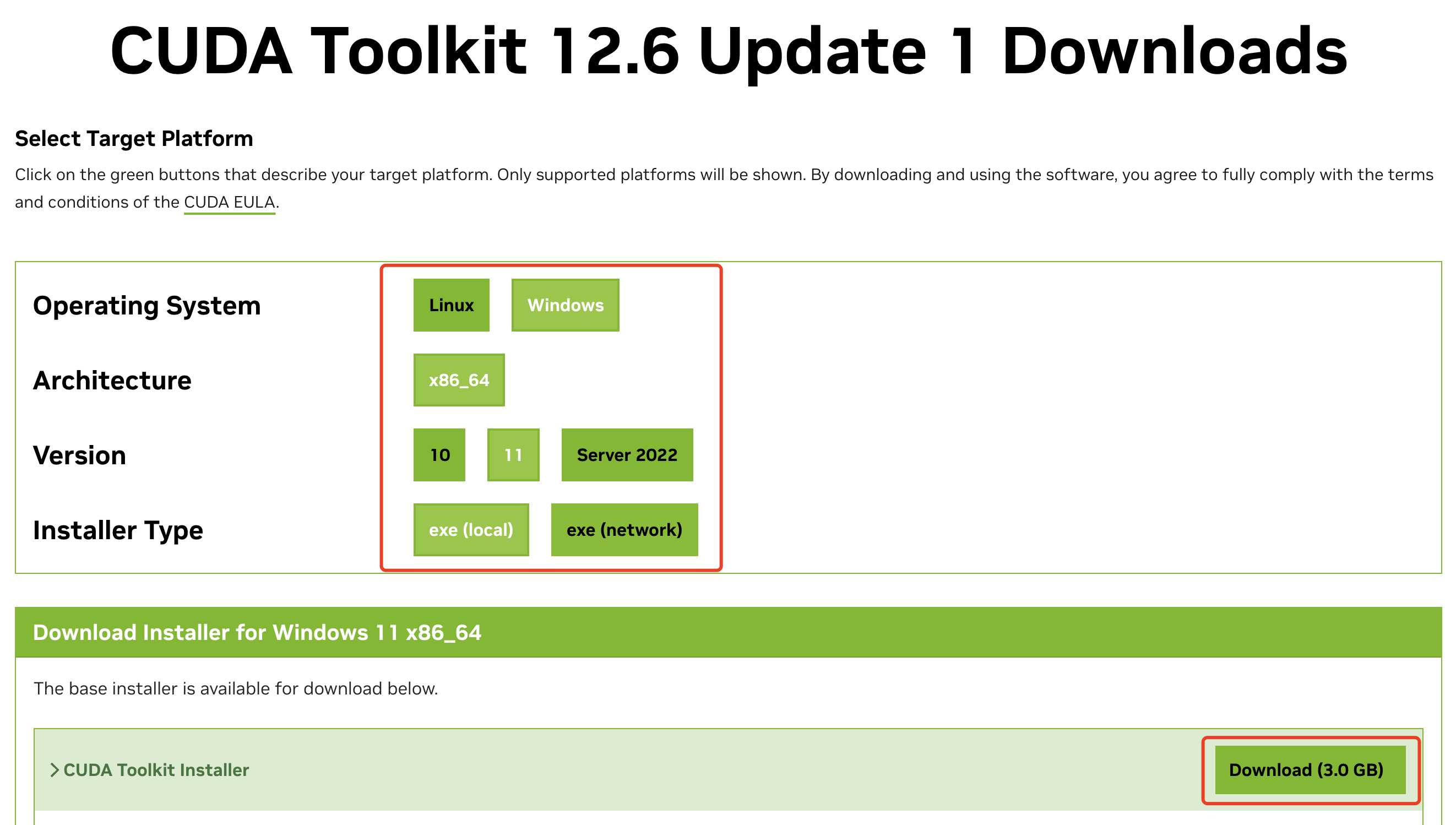
下载的 CUDA Toolkit 版本不能高于显卡自身支持的 CUDA 版本。本例中,则不能下载高于 12.6 版本的 CUDA Toolkit 工具包
- 核对完成后,前往 NVIDIA 官网下载(https://developer.nvidia.com/cuda-toolkit-archive)
- 选择好系统和离线安装模式
exe(local),然后点击下载
- 双击启动下载的文件,第一步是提取安装程序,路径默认即可,这不是安装的最终路径
- 提取完成后,出现如下安装界面
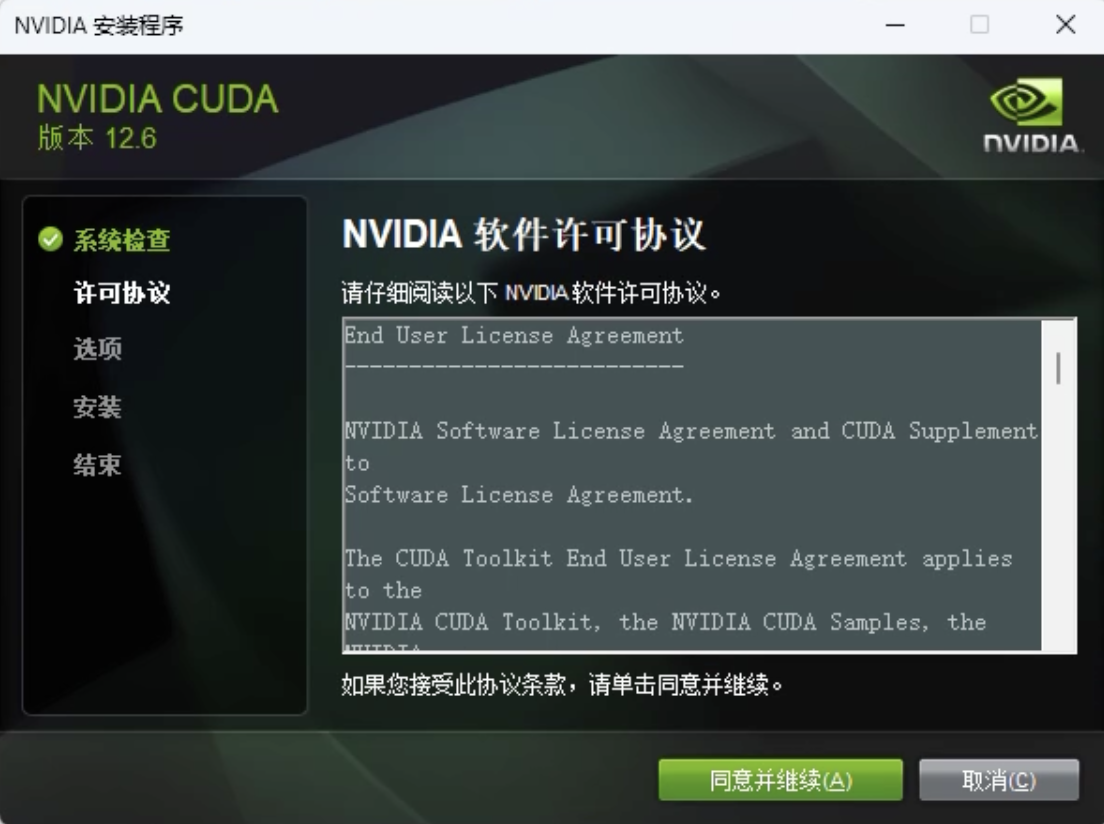
- 选择自定义安装
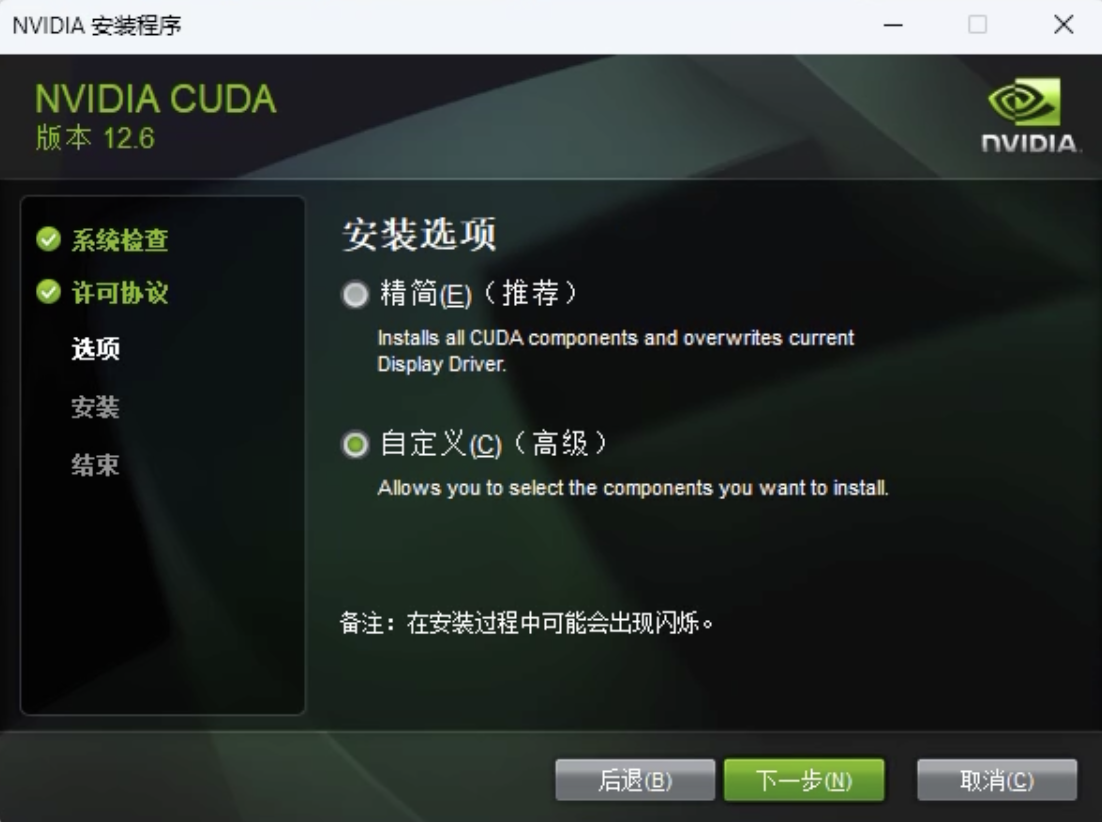
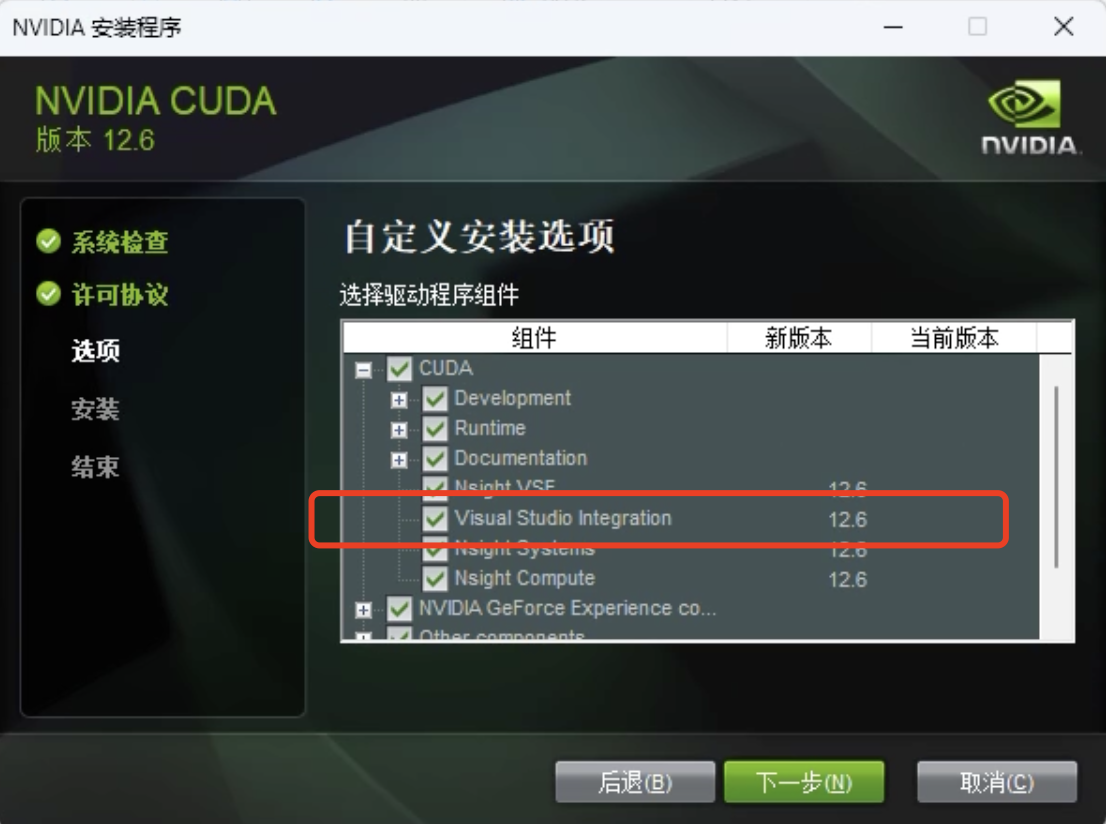
- 勾选安装组件
默认情况下是全部勾选,其中,Visual Studio Integration 是为你的 VS 提供 CUDA 编程相关的模版等集成组件,如果你不想在 VS 中进行编程,可以不勾选,这里我保持勾选
- 选择好安装位置后,点击下一步进行安装
- 等待安装完成
- 配置系统环境变量
根据自己安装的路径进行修改
① Visual Studio 的 bin 路径
D:\software\visualstudio\2022\Community\VC\Tools\MSVC\14.41.34120\bin\Hostx64\x64
② CUDA 相关 bin 和 lib 路径
D:\software\cuda\v12.6\binD:\software\cuda\v12.6\lib\x64
3.4 验证是否安装成功
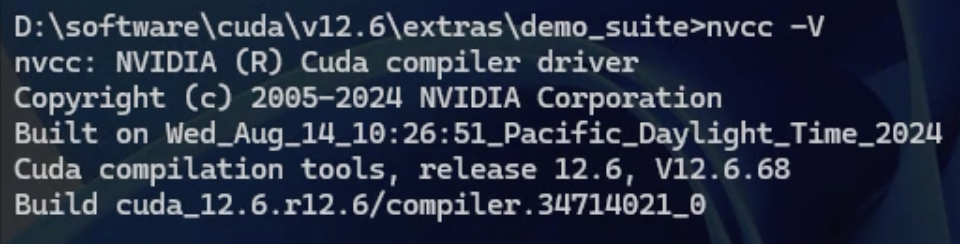
- 在命令行中输入:
nvcc -V查看nvcc编译器版本
deviceQuery.exe与bandwidthTest.exe两个可执行程序是否能够正常运行。- 所在位置为:
{cuda 安装路径}\extras\demo_suite
- 所在位置为:
# 先切换到cuda所在盘D:# 进入该路径cd D:\software\cuda\v12.6\extras\demo_suite- 执行
deviceQuery.exe

- 执行
bandwidthTest.exe
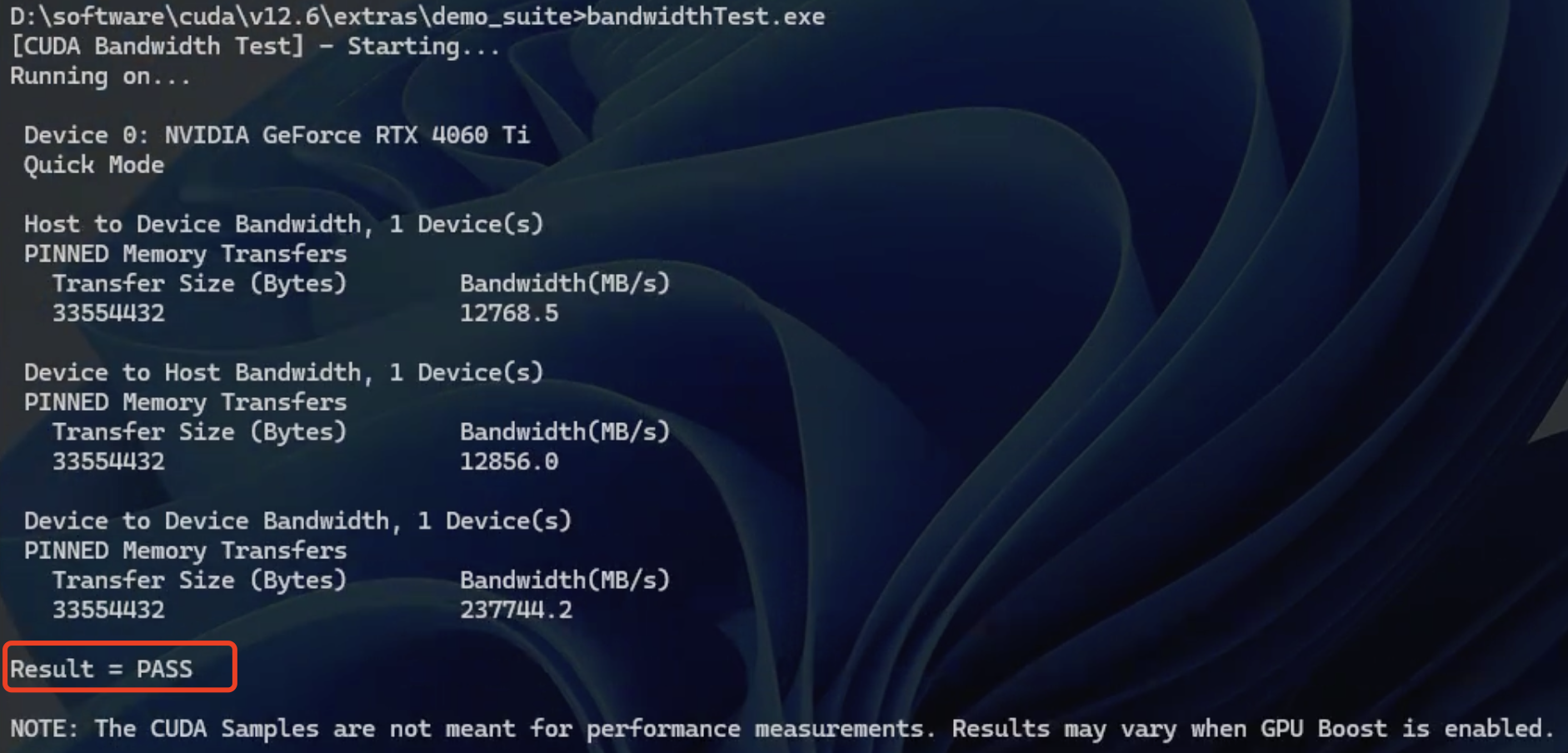
- 在命令行中运行上述两个可执行程序,运行结果为
result=PASS则说明 CUDA 安装成功
4 VS2022 下配置 CUDA 调试环境(方法一)
要求在安装cuda时,勾选了 cuda 与 vs 的集成组件
- 直接创建 CUDA 项目
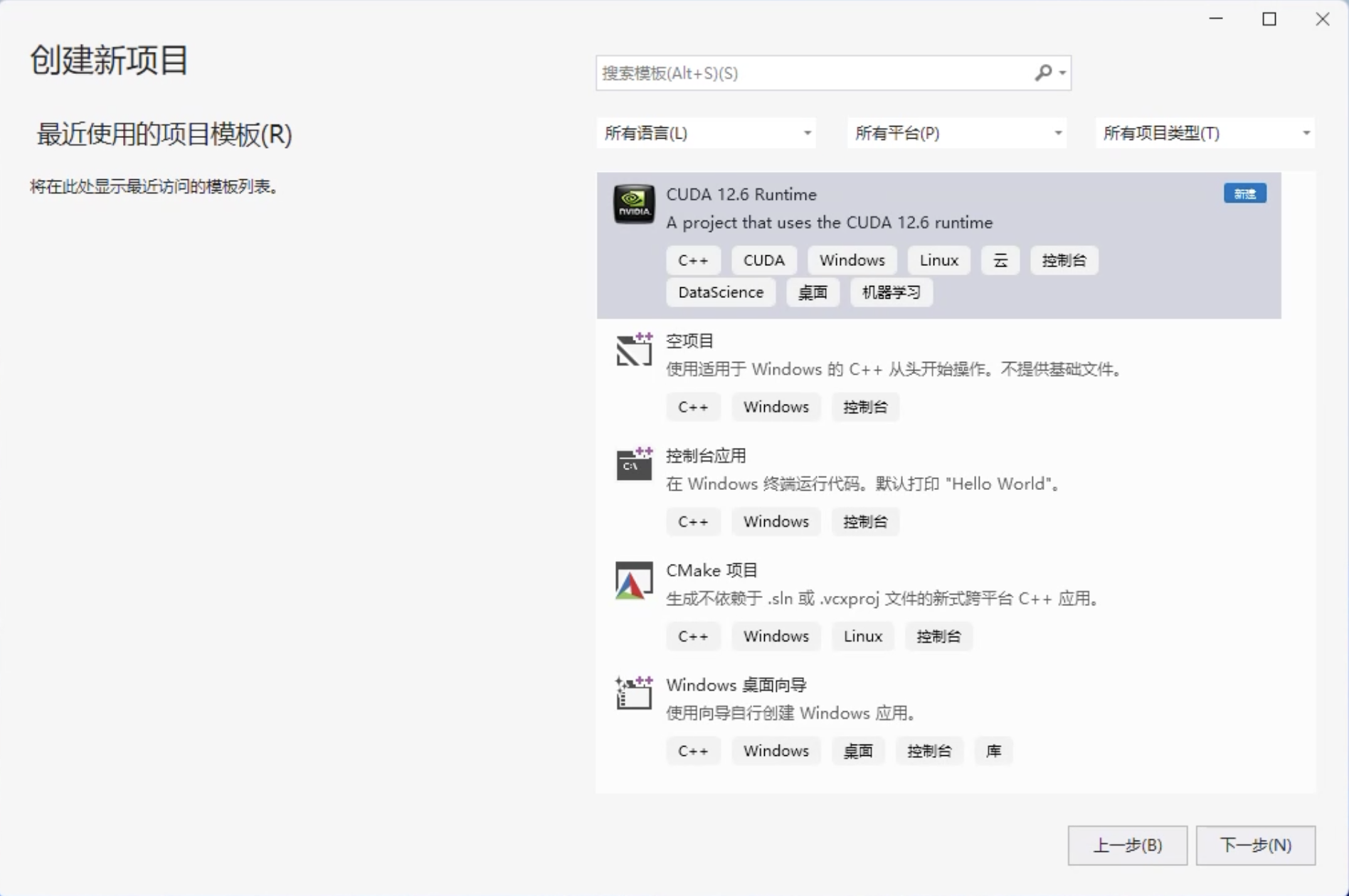
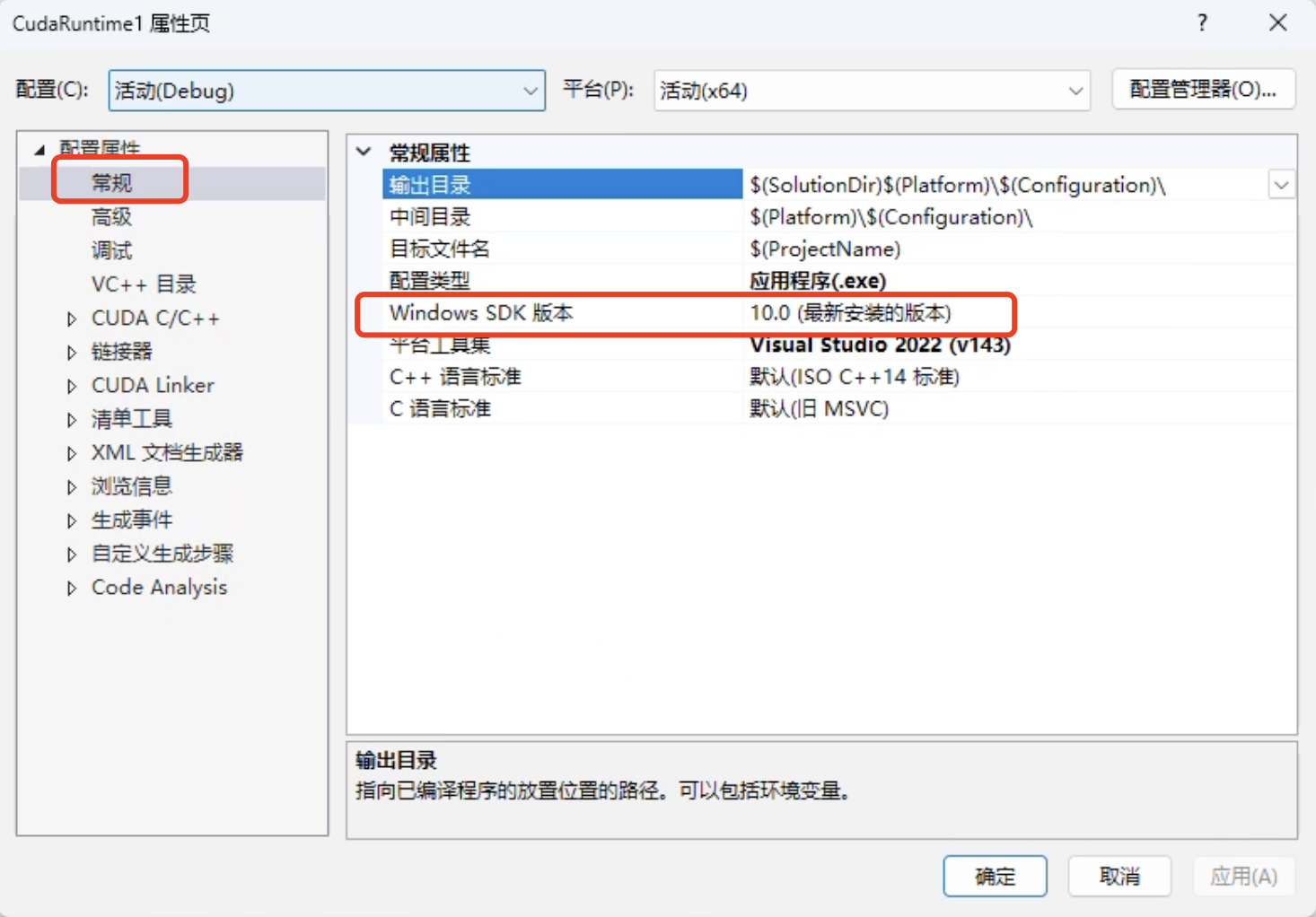
- 如果出现不识别
stdio.h库的情况,可以修改Windows SDK版本,如下所示: - 右键,点击属性,这里可以修改
Windows SDK版本
5 VS2022 下配置 CUDA 调试环境(方法二)
- 新建空项目
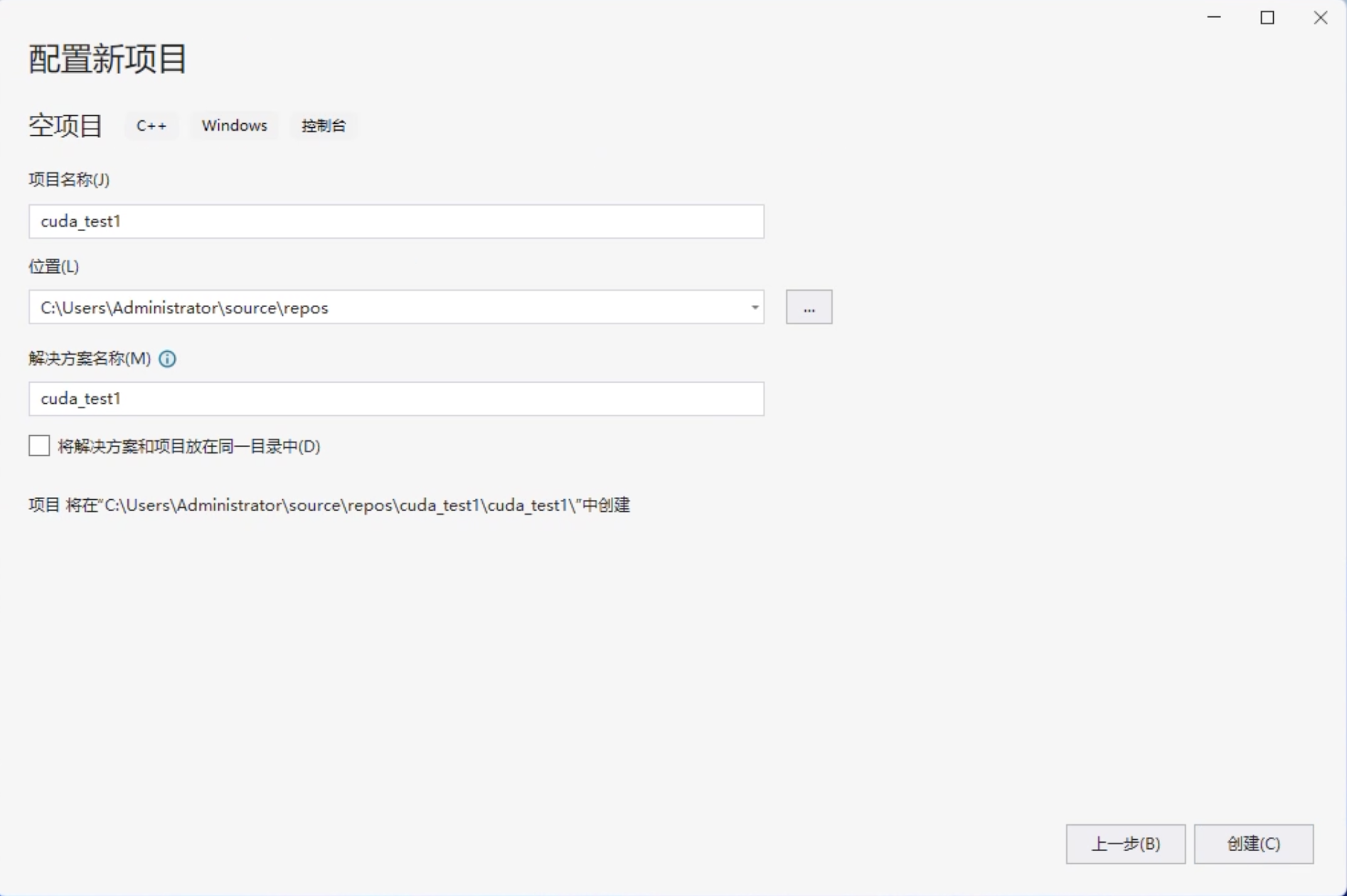
- 生成依赖项
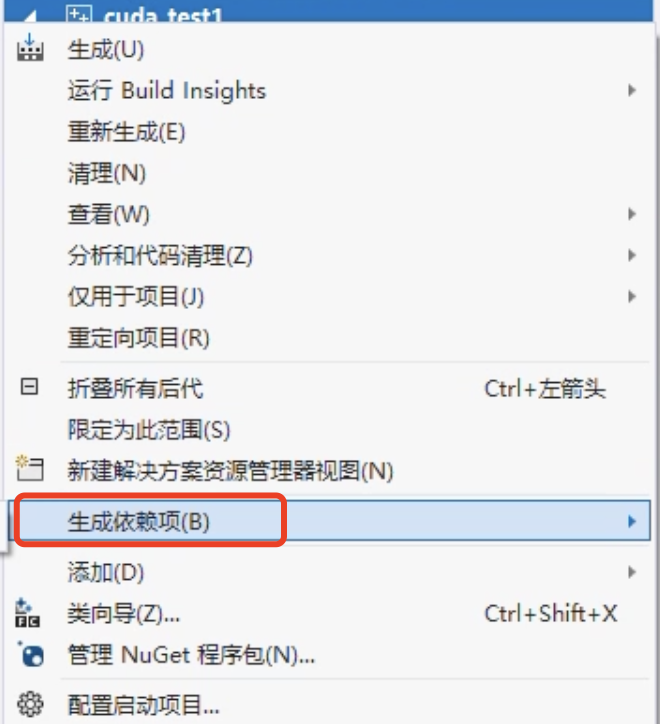
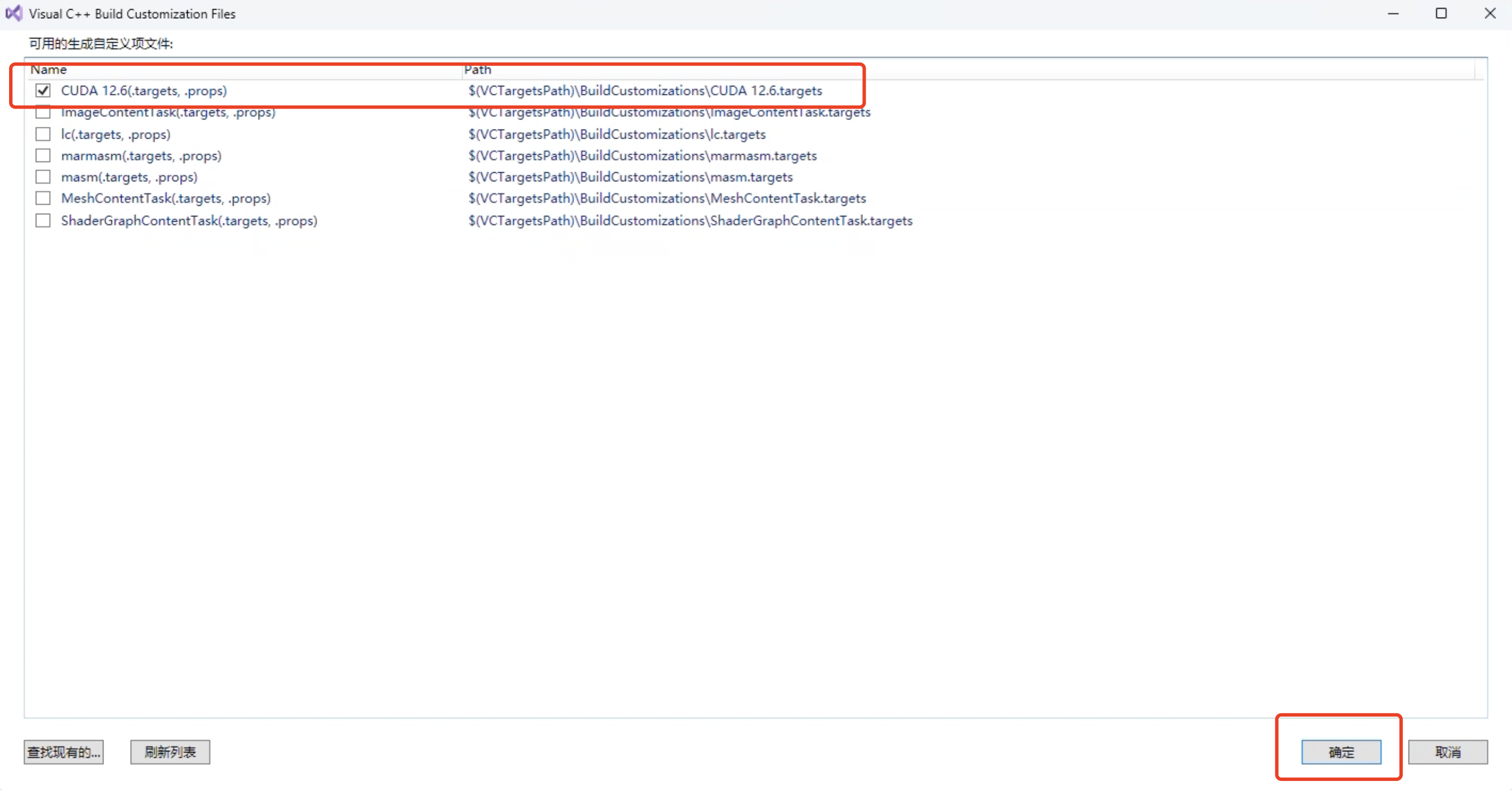
- 勾选 cuda,点击确定
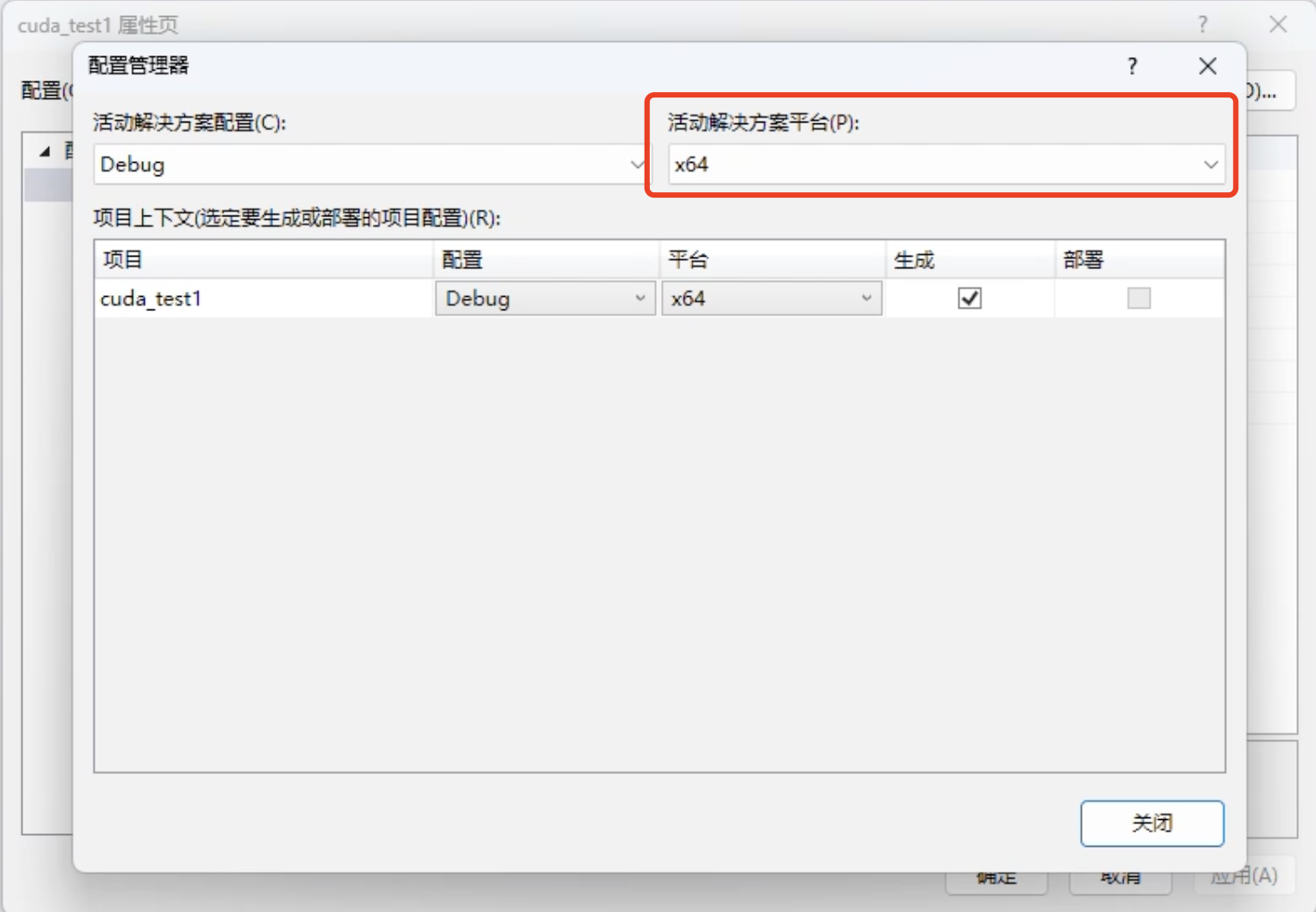
- 配置管理器
右键点击项目属性 → 配置管理器
与自己电脑 CPU 架构一致
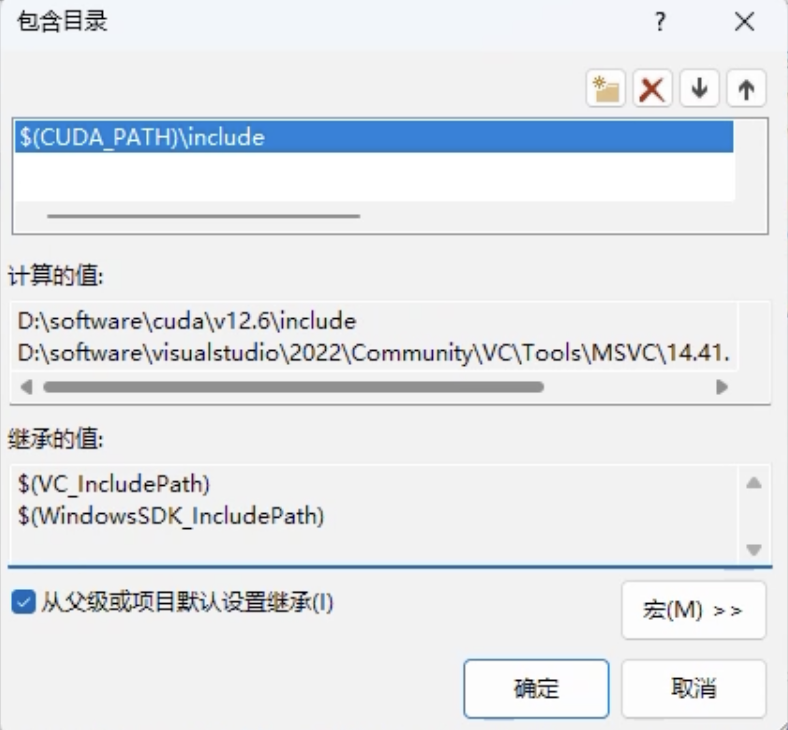
- 配置包含目录
右键点击项目属性 → 配置属性 → VC++ 目录 → 包含目录
添加包含目录:
$(CUDA_PATH)\include
- 配置库目录
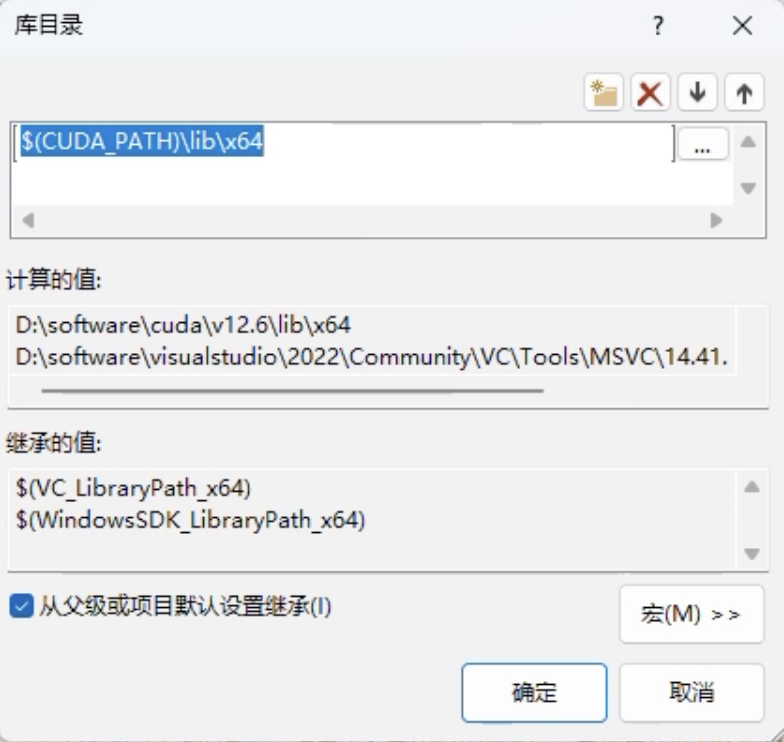
VC++ 目录 → 库目录
添加库目录:
$(CUDA_PATH)\lib\x64
- 配置依赖项
配置属性 → 链接器 → 输入 → 附加依赖项
将该目录下的库文件添加进去
默认路径为:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\lib\x64本例中路径为:
D:\software\cuda\v12.6\lib\x64

cublas.libcublasLt.libcuda.libcudadevrt.libcudart.libcudart_static.libcufft.libcufftw.libcufilt.libcurand.libcusolver.libcusolverMg.libcusparse.libnppc.libnppial.libnppicc.libnppidei.libnppif.libnppig.libnppim.libnppist.libnppisu.libnppitc.libnpps.libnvblas.libnvfatbin.libnvfatbin_static.libnvJitLink.libnvJitLink_static.libnvjpeg.libnvml.libnvptxcompiler_static.libnvrtc-builtins_static.libnvrtc.libnvrtc_static.libOpenCL.lib6 CUDA 编程测试
可以打开 VS 并创建一个 CUDA Runtime 工程,在
kernel.cu文件中修改代码也可以在命令行进行测试,这里我以在 GPU 服务器上为例进行演示
6.1 两个数组相加的简单例子
在服务器上,程序我已经帮大家写好了
在
/home/temp/user*/目录下

- 进入到该目录,我以
user1为例
cd /home/temp/user1- 查看该目录下的
cuda程序
serial.cu:串行程序
parallel_*.cu:并行程序
ls
- 单线程执行程序代码:
#include <iostream> #include <math.h> #include <ctime> using namespace std;// 数组元素相加的函数 void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i];}int main(void) { clock_t startTime, endTime; startTime = clock();//计时开始 int N = 1 << 20; // 1M 元素 float *x = new float[N]; float *y = new float[N]; // 在主机端初始化数组 for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // 执行函数 add(N, x, y); // 检查误差 (所有的值应该是 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i] - 3.0f)); std::cout << "Max error: " << maxError << std::endl; endTime = clock(); // 计时结束 cout << "The run time is: " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl; // 释放内存 delete[] x; delete[] y; return 0;}- 编译并执行
nvcc serial.cu -o serial ./serial
- GPU 并行化执行程序代码:
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <iostream> #include <math.h> #include <ctime> using namespace std;// 两个数组相加的核函数,指示符__global__告诉编译器该函数是运行在 // GPU 上,称为核函数 __global__ void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i];}int main(void) { clock_t startTime, endTime; startTime = clock(); // 计时开始 int N = 1 << 20; float *x, *y; // 分配共享内存 – CPU 和 GPU 都可以访问 cudaMallocManaged(&x, N * sizeof(float)); cudaMallocManaged(&y, N * sizeof(float)); // 在主机端初始化数组 for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // 在 GPU 上执行核函数 add <<<1,1>>> (N, x, y); // 等待 GPU 执行完毕 cudaDeviceSynchronize(); // 检查误差 (所有的值应该是 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i] - 3.0f)); std::cout << "Max error: " << maxError << std::endl; // 释放内存 cudaFree(x); cudaFree(y); endTime = clock(); // 计时结束 cout << "The run time is: " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl; return 0;}- 编译并执行
nvcc parallel_1.cu -o parallel_1./parallel_1
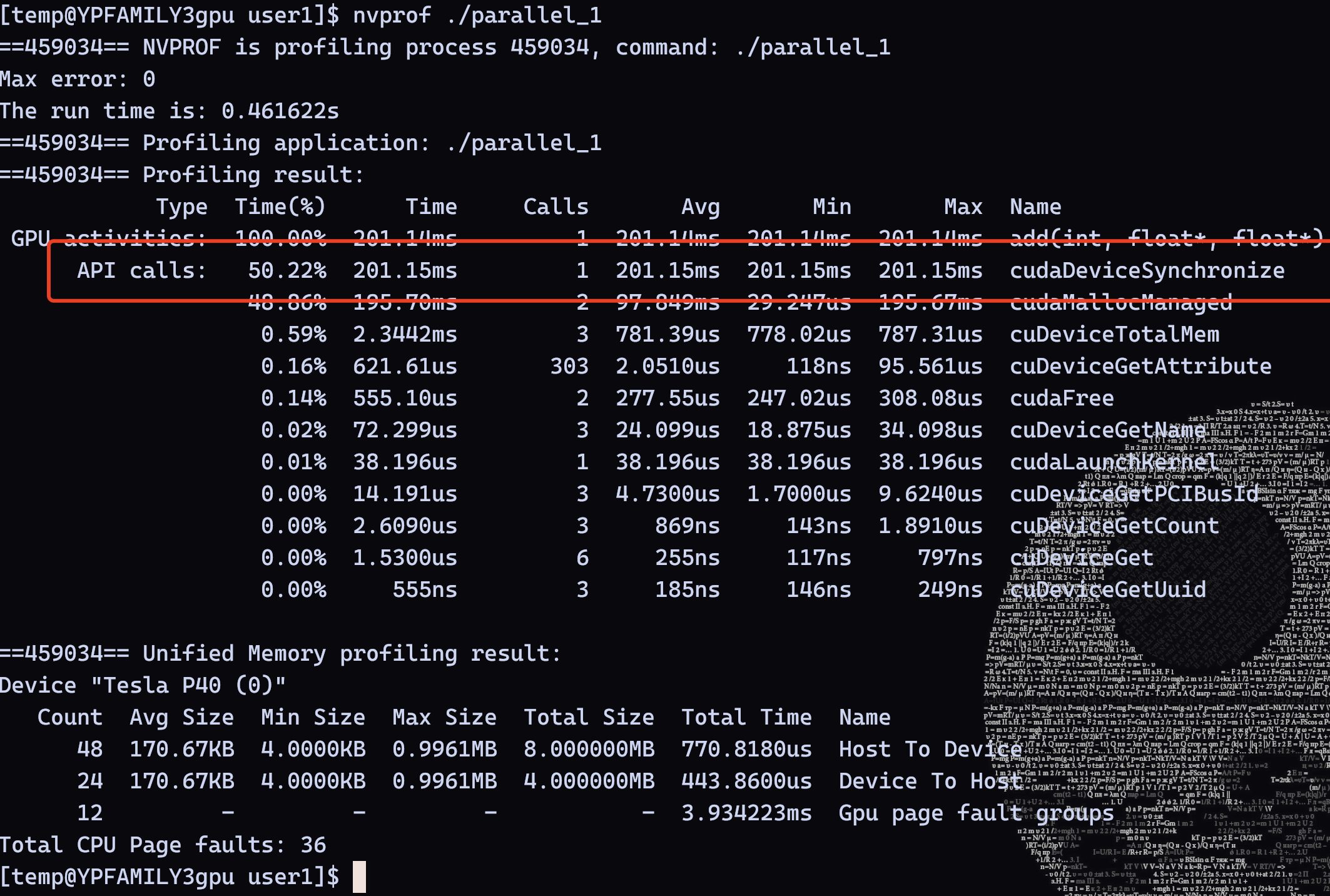
从结果上看,可以发现程序耗时
1.5433s,超过了单线程程序耗时0.012454s这其中大部分时间时间花在了 GPU 的 API calls 上面,这是由于给 GPU 分配共享内存会额外消耗时间
我们可以使用
nvprof工具进行分析
- 在Windows下,可以按照下列步骤执行:
- 程序编译后在工程目录下生成可执行程序,如
CudaRuntime1.exe- 进入到
CudaRuntime1.exe所在目录- 执行
nvprof CudaRuntime1.exe附:如果报错(由于找不到cupti64_2024.3.1.dll,无法继续执行代码。重新安装程序可能会解决此问题)
则需要将
CUPTI库所在路径添加到环境变量默认是:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\extras\CUPTI\lib64
- 在服务器上,我们直接继续执行如下命令即可
nvprof ./parallel_1我们可以发现
api calls耗时占据非常多
- 可以进一步修改
add函数,将计算分配到各个线程上(其中threadIdx.x是线程号,blockDim.x是线程块中拥有的线程数量),这里我们直接提供了修改后的代码,即parallel_2.cu:
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <iostream> #include <math.h> #include <ctime> using namespace std;// 两个数组相加的核函数,指示符__global__告诉编译器该函数是运行在 // GPU 上,称为核函数 __global__ void add(int n, float *x, float *y){int index = threadIdx.x;int stride = blockDim.x;for (int i = index; i < n; i += stride) y[i] = x[i] + y[i];}int main(void) { clock_t startTime, endTime; startTime = clock(); // 计时开始 int N = 1 << 20; float *x, *y; // 分配共享内存 – CPU 和 GPU 都可以访问 cudaMallocManaged(&x, N * sizeof(float)); cudaMallocManaged(&y, N * sizeof(float)); // 在主机端初始化数组 for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // 在 GPU 上执行核函数 add <<<1,1>>> (N, x, y); // 等待 GPU 执行完毕 cudaDeviceSynchronize(); // 检查误差 (所有的值应该是 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i] - 3.0f)); std::cout << "Max error: " << maxError << std::endl; // 释放内存 cudaFree(x); cudaFree(y); endTime = clock(); // 计时结束 cout << "The run time is: " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl; return 0;}- 编译并执行
parallel_2.cu,查看运行时间,可以发现耗时与之前基本一样,这是由于之前调用核函数时设置的线程数只为 1
nvcc parallel_2.cu -o parallel_2nvprof ./parallel_2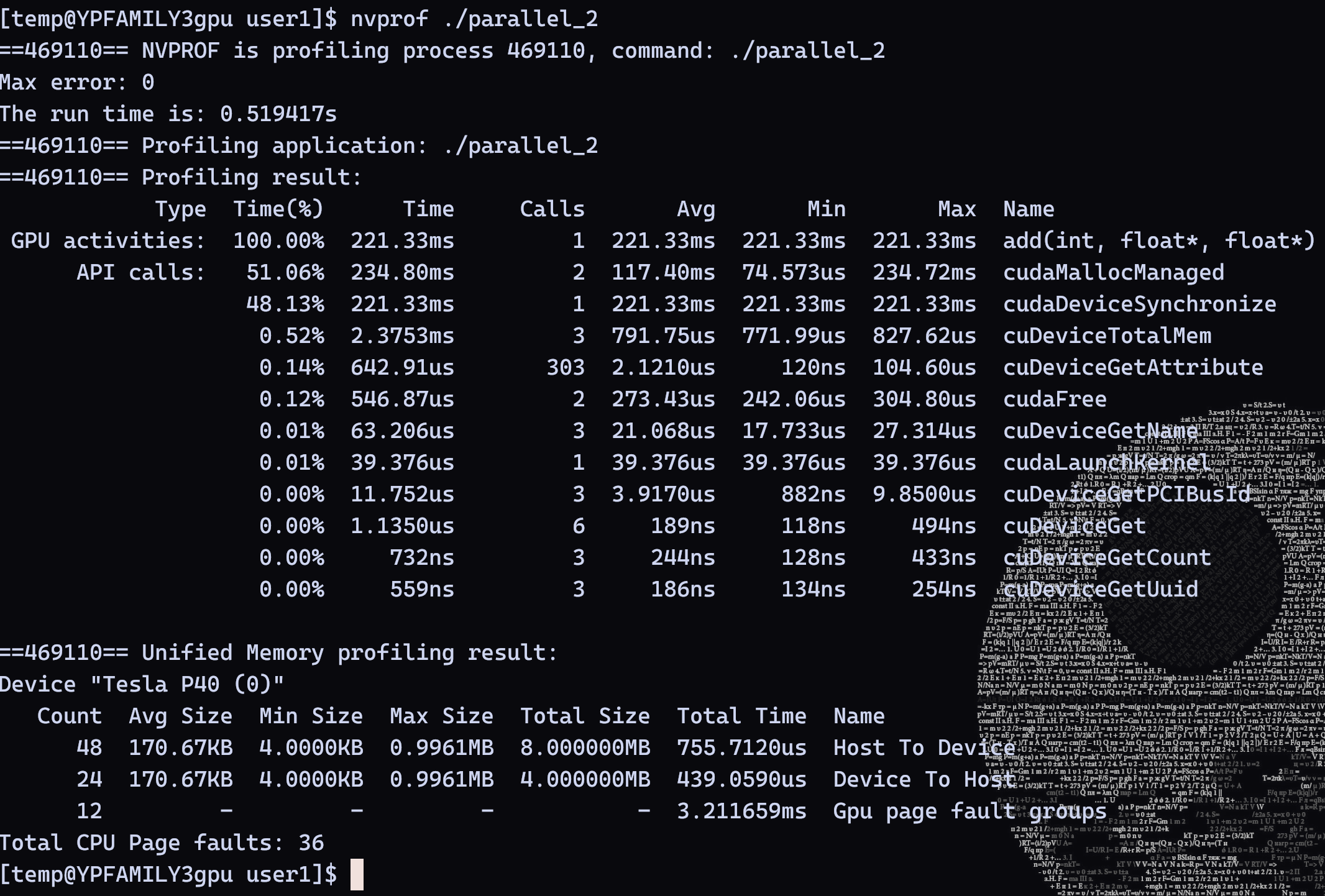
CUDA 核函数使用三尖括号语法
<<< >>>指定。第一个参数代表线程块数 (block)、第二个参数代表每个线程块的线程数(thread),线程数最好是 32 的倍数,如 256:
int blockSize = 256;int numBlocks = (N + blockSize - 1) / blockSize;add<<<numBlocks, blockSize>>>(N, x, y);注:也可通过修改参数来控制并行度 , 例如:
add<<<numBlocks/2, blockSize>>>(N, x, y)同时,修改
add函数(其中,blockIdx.x表示线程块号)
__global__ void add(int n, float *x, float *y){int index = blockIdx.x * blockDim.x + threadIdx.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < n; i += stride) y[i] = x[i] + y[i];}- 这里我们也直接给出了修改后的代码,即
parallel_3.cu
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <iostream> #include <math.h> #include <ctime> using namespace std;// 两个数组相加的核函数,指示符__global__告诉编译器该函数是运行在 // GPU 上,称为核函数 __global__ void add(int n, float *x, float *y){int index = blockIdx.x * blockDim.x + threadIdx.x;int stride = blockDim.x * gridDim.x;for (int i = index; i < n; i += stride) y[i] = x[i] + y[i];}int main(void) { clock_t startTime, endTime; startTime = clock(); // 计时开始 int N = 1 << 20; float *x, *y; int blockSize = 256; int numBlocks = (N + blockSize - 1) / blockSize; add<<<numBlocks, blockSize>>>(N, x, y); // 分配共享内存 – CPU 和 GPU 都可以访问 cudaMallocManaged(&x, N * sizeof(float)); cudaMallocManaged(&y, N * sizeof(float)); // 在主机端初始化数组 for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // 在 GPU 上执行核函数 add <<<1,1>>> (N, x, y); // 等待 GPU 执行完毕 cudaDeviceSynchronize(); // 检查误差 (所有的值应该是 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i] - 3.0f)); std::cout << "Max error: " << maxError << std::endl; // 释放内存 cudaFree(x); cudaFree(y); endTime = clock(); // 计时结束 cout << "The run time is: " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl; return 0;}- 编译并执行
parallel_3.cu,查看运行时间
nvcc parallel_3.cu -o parallel_3nvprof ./parallel_3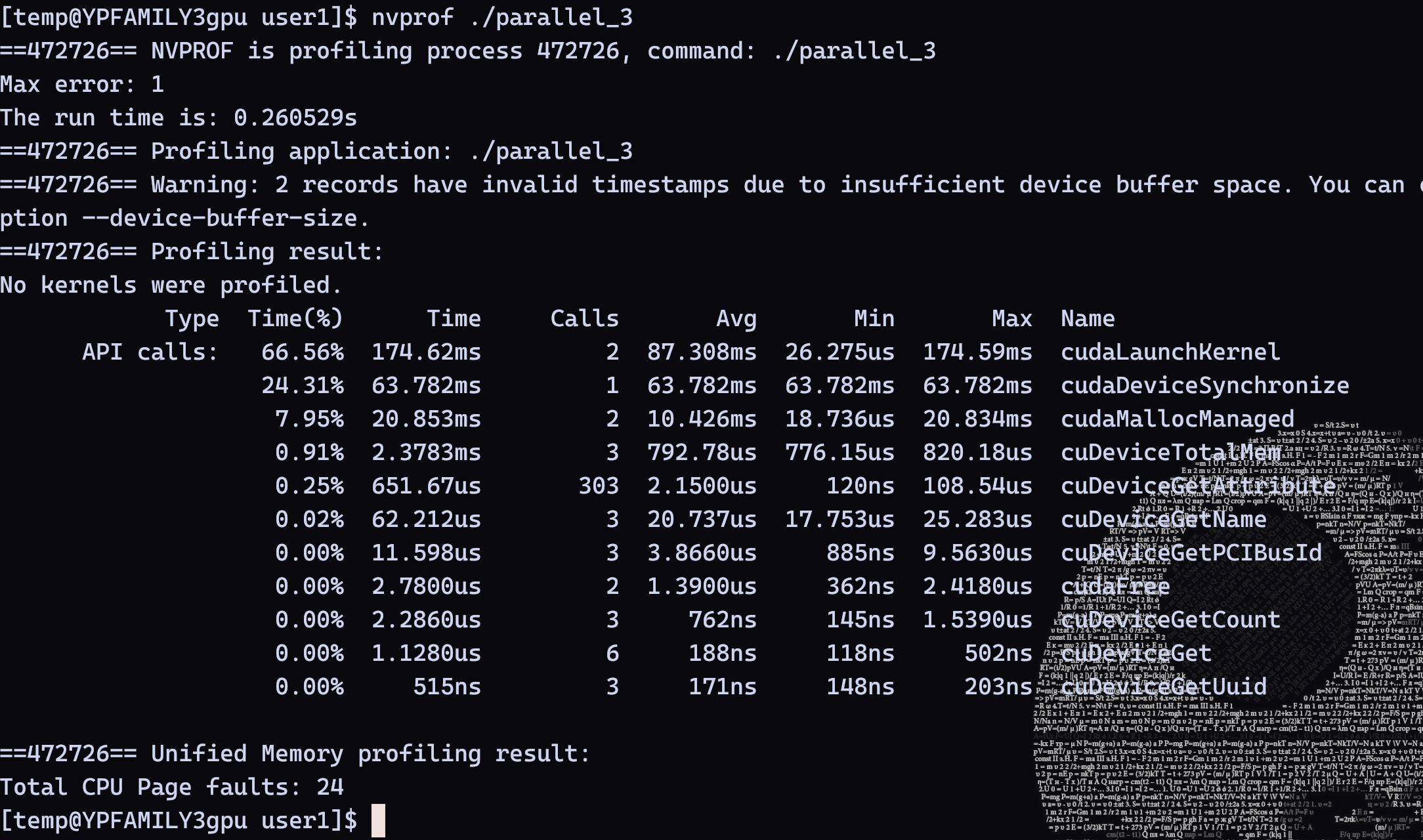
从结果上看,可以看到总耗时降低到了
0.260529s,api calls花了0.063782s
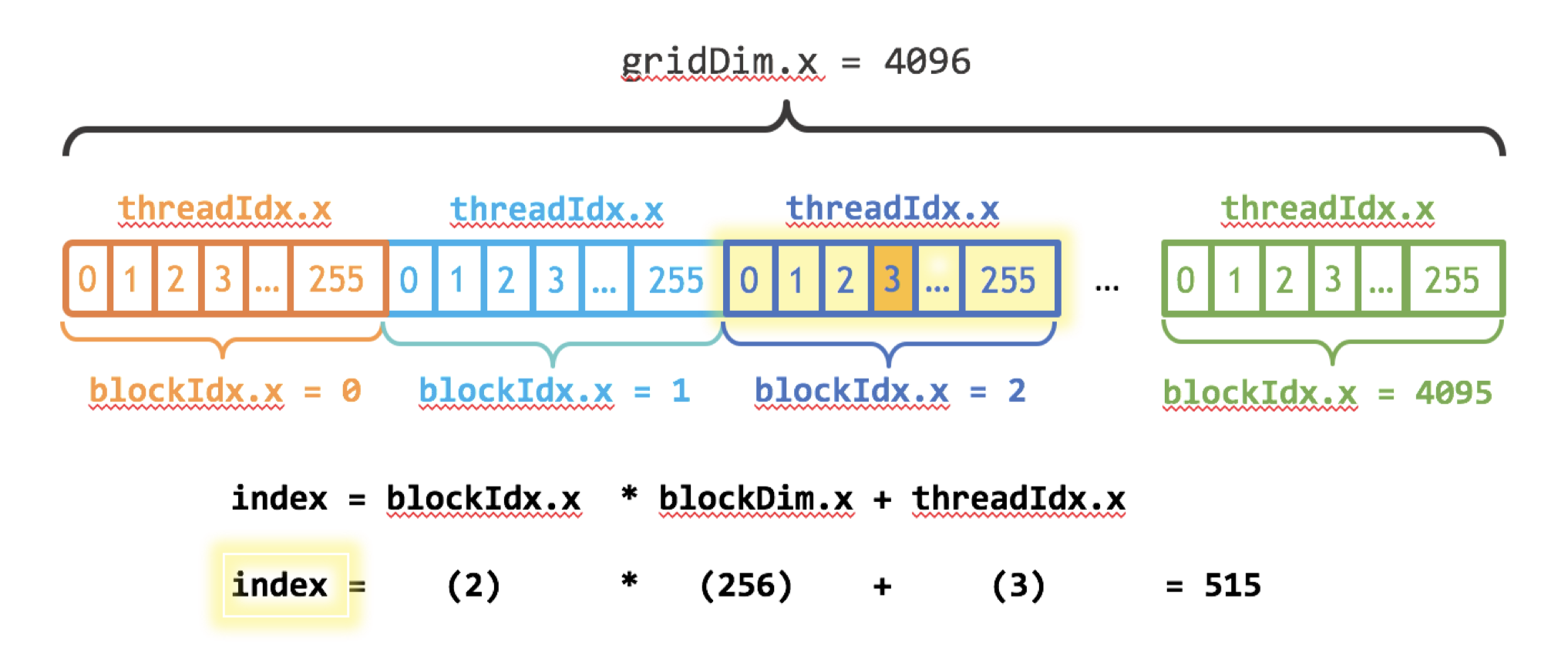
gridDim.x表示线程格(grid,由多个线程块组成)中线程块的数量
blockIdx.x * blockDim.x + threadIdx.x // 线程号